请注意,本文编写于 522 天前,最后修改于 246 天前,其中某些信息可能已经过时。
Python单线程与多线程
最近一直在学习爬虫的相关知识,目前学习到了单线程、多线程这一块,把自己的学习经历分享出来顺便也做个笔记。
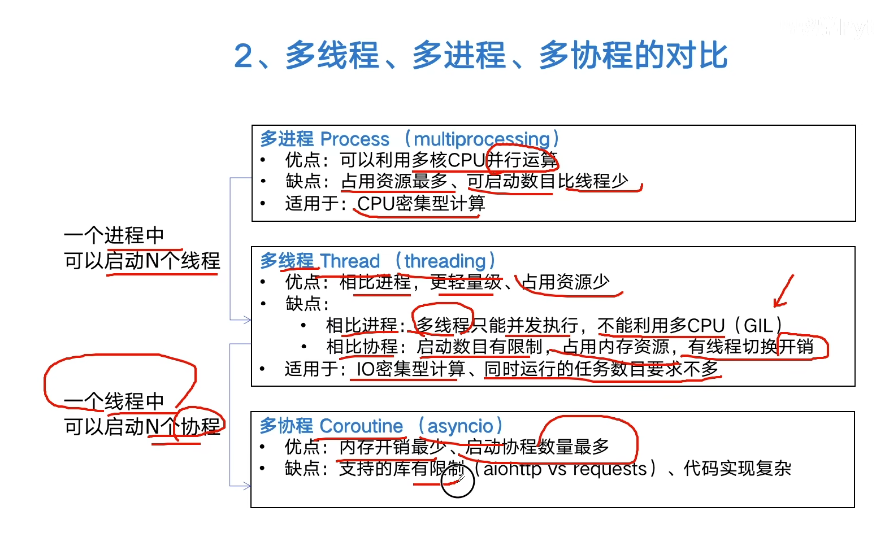
多线程与多进程
首先我们要明白,单线程、多线程、多进程、多机器
简单来说如下图所示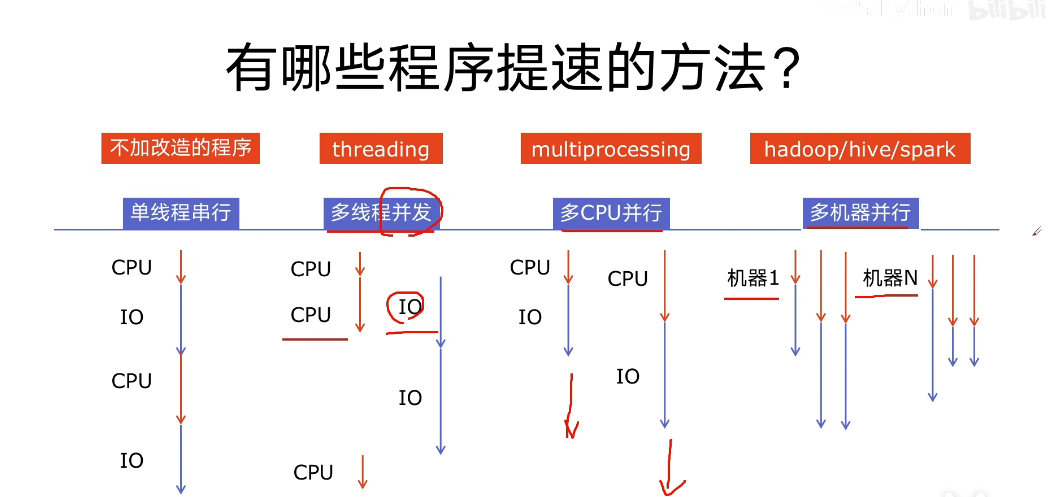
在写程序时经常要合理选择多线程与多进程,这两者各有优势,并不存在谁好谁坏,根据需求来进行选择,
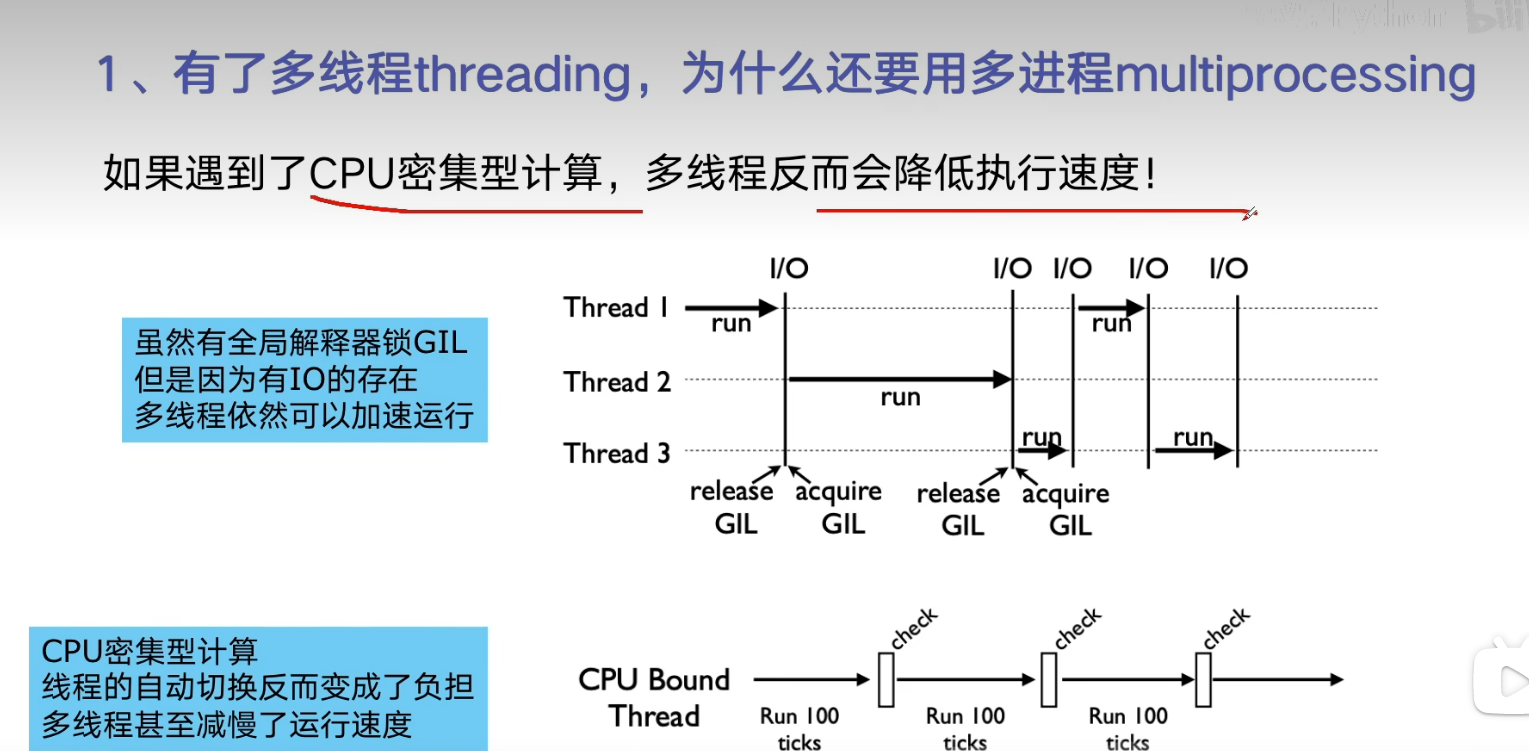
一般多线程适合I/O密集型,多进程适合CPU密集型
一.单线程操作
单线程操作就是我们日常写代码时的操作,为了比较出和多线程的区别,以下为其对比。
#使用单线程串行方式执行
import time
def get_page(str):
print('正在下载:',str)
time.sleep(2)
print('下载成功:',str)
name_list = ['xiaozi','aa','bb','cc']
start_time = time.time()
for i in range(len(name_list)):
get_page(name_list[i])
end_time = time.time()
print('%d second' % (end_time-start_time))正在下载: xiaozi
下载成功: xiaozi
正在下载: aa
下载成功: aa
正在下载: bb
下载成功: bb
正在下载: cc
下载成功: cc
8 second二.多线程操作
循环
首先引入多线程模块
import time
import threading
def get_page(str):
print('正在下载:',str,'\n')
time.sleep(2)
print('下载成功:',str,'\n')
name_list = ['xiaozi','aa','bb','cc']
start_time = time.time()
for name in name_list:
t = threading.Thread(target=get_page,args=(name,))
t.start()运行之后可以发现
正在下载: xiaozi
正在下载: aa
正在下载: bb
正在下载: cc
下载成功: xiaozi
下载成功: aa
下载成功: cc
下载成功: bb
2 second池化
import time
from concurrent.futures import ThreadPoolExecutor,as_completed
def get_page(str):
print('正在下载:',str,'\n')
time.sleep(2)
print('下载成功:',str,'\n')
name_list = ['xiaozi','aa','bb','cc']
start_time = time.time()
with ThreadPoolExecutor() as pool:
# 方法一
results = pool.map(get_page,name_list)
for result in results:
print(result)
#方法二
futures = [pool.submit(get_page,name) for name in name_list]
# 方法二的第一种输出方法,按照顺序,会堵塞
for future in futures:
print(future.result())
# 方法二的第二种输出方法,不按照顺序,不会堵塞
for future in as_completed(futures):
print(future.result())二.多进程操作
循环
import time
from multiprocessing import Process
def get_page(str):
print('正在下载:',str,'\n')
time.sleep(2)
print('下载成功:',str,'\n')
name_list = ['xiaozi','aa','bb','cc']
start_time = time.time()
for name in name_list:
t = Process(target=get_page,args=(name,))
t.start()池化
import time
from concurrent.futures import ProcessPoolExecutor,as_completed
def get_page(str):
print('正在下载:',str,'\n')
time.sleep(2)
print('下载成功:',str,'\n')
name_list = ['xiaozi','aa','bb','cc']
start_time = time.time()
with ProcessPoolExecutor() as pool:
# 方法一
results = pool.map(get_page,name_list)
for result in results:
print(result)
#方法二
futures = [pool.submit(get_page,name) for name in name_list]
# 方法二的第一种输出方法,按照顺序,会堵塞
for future in futures:
print(future.result())
# 方法二的第二种输出方法,不按照顺序,不会堵塞
for future in as_completed(futures):
print(future.result())目前我个人来说使用的方式一般是单线程+异步协程。
我将在下一篇文章中进行相关的记录,说明。
希望大家给点个赞,如有错误,望指出。
